
Kubernetes K8S之Node节点亲和性与反亲和性以及Pod亲和性与反亲和性详解与示例
主机配置规划
| 服务器名称(hostname) | 系统版本 | 配置 | 内网IP | 外网IP(模拟) |
|---|---|---|---|---|
| k8s-master | CentOS7.7 | 2C/4G/20G | 172.16.1.110 | 10.0.0.110 |
| k8s-node01 | CentOS7.7 | 2C/4G/20G | 172.16.1.111 | 10.0.0.111 |
| k8s-node02 | CentOS7.7 | 2C/4G/20G | 172.16.1.112 | 10.0.0.112 |
亲和性和反亲和性
nodeSelector提供了一种非常简单的方法,将pods约束到具有特定标签的节点。而亲和性/反亲和性极大地扩展了可表达的约束类型。关键的增强是:
1、亲和性/反亲和性语言更具表达性。除了使用逻辑AND操作创建的精确匹配之外,该语言还提供了更多的匹配规则;
2、可以指示规则是优选项而不是硬要求,因此如果调度器不能满足,pod仍将被调度;
3、可以针对节点(或其他拓扑域)上运行的pods的标签进行约束,而不是针对节点的自身标签,这影响哪些Pod可以或不可以共处。
亲和特性包括两种类型:node节点亲和性/反亲和性 和 pod亲和性/反亲和性。pod亲和性/反亲和性约束针对的是pod标签而不是节点标签。
拓扑域是什么:多个node节点,拥有相同的label标签【节点标签的键值相同】,那么这些节点就处于同一个拓扑域。★★★★★
node节点亲和性
当前有两种类型的节点亲和性,称为requiredDuringSchedulingIgnoredDuringExecution和 preferredDuringSchedulingIgnoredDuringExecution,可以将它们分别视为“硬”【必须满足条件】和“软”【优选满足条件】要求。
前者表示Pod要调度到的节点必须满足规则条件,不满足则不会调度,pod会一直处于Pending状态;后者表示优先调度到满足规则条件的节点,如果不能满足再调度到其他节点。
名称中的 IgnoredDuringExecution 部分意味着,与nodeSelector的工作方式类似,如果节点上的标签在Pod运行时发生更改,使得pod上的亲和性规则不再满足,那么pod仍将继续在该节点上运行。
在未来,会计划提供requiredDuringSchedulingRequiredDuringExecution,类似requiredDuringSchedulingIgnoredDuringExecution。不同之处就是pod运行过程中如果节点不再满足pod的亲和性,则pod会在该节点中逐出。
节点亲和性语法支持以下运算符:In,NotIn,Exists,DoesNotExist,Gt,Lt。可以使用NotIn和DoesNotExist实现节点的反亲和行为。
运算符关系:
- In:label的值在某个列表中
- NotIn:label的值不在某个列表中
- Gt:label的值大于某个值
- Lt:label的值小于某个值
- Exists:某个label存在
- DoesNotExist:某个label不存在
1、如果同时指定nodeSelector和nodeAffinity,则必须满足两个条件,才能将Pod调度到候选节点上。
2、如果在nodeAffinity类型下指定了多个nodeSelectorTerms对象【对象不能有多个,如果存在多个只有最后一个生效】,那么只有最后一个nodeSelectorTerms对象生效。
3、如果在nodeSelectorTerms下指定了多个matchExpressions列表,那么只要能满足其中一个matchExpressions,就可以将pod调度到某个节点上【针对节点硬亲和】。
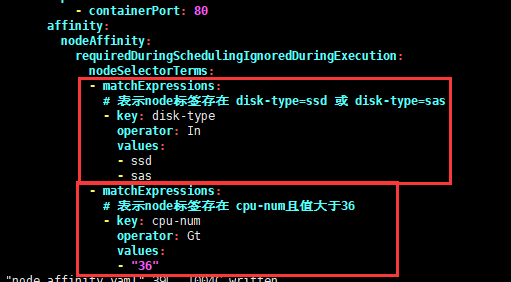
4、如果在matchExpressions下有多个key列表,那么只有当所有key满足时,才能将pod调度到某个节点【针对硬亲和】。
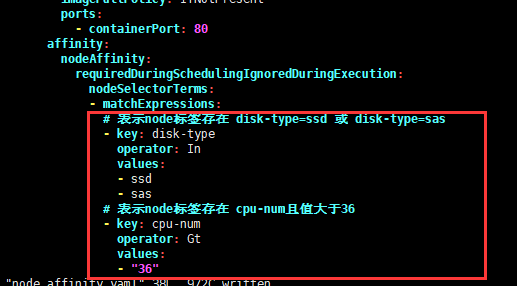
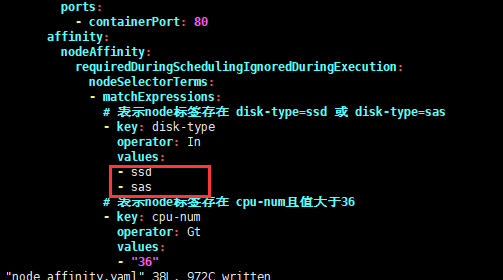
5、在key下的values只要有一个满足条件,那么当前的key就满足条件
6、如果pod已经调度在该节点,当我们删除或修该节点的标签时,pod不会被移除。换句话说,亲和性选择只有在pod调度期间有效。
7、preferredDuringSchedulingIgnoredDuringExecution中的weight(权重)字段在1-100范围内。对于每个满足所有调度需求的节点(资源请求、RequiredDuringScheduling亲和表达式等),调度器将通过迭代该字段的元素来计算一个总和,如果节点与相应的匹配表达式匹配,则向该总和添加“权重”。然后将该分数与节点的其他优先级函数的分数结合起来。总得分最高的节点是最受欢迎的。
node节点亲和性示例
准备事项
给node节点打label标签
1 | ### --overwrite覆盖已存在的标签信息 |
查询所有节点标签信息
1 | [root@k8s-master ~]# kubectl get node -o wide --show-labels |
参见上面,给k8s-node01打了cpu-num=12,disk-type=ssd标签;给k8s-node02打了cpu-num=24,disk-type=sata标签。
node硬亲和性示例
必须满足条件才能调度,否则不会调度
要运行的yaml文件
1 | [root@k8s-master nodeAffinity]# pwd |
运行yaml文件并查看状态
1 | [root@k8s-master nodeAffinity]# kubectl apply -f node_required_affinity.yaml |
由上可见,再根据之前打的标签,很容易推断出当前pod只能调度在k8s-node01节点。
即使我们删除原来的rs,重新生成rs后pod依旧会调度到k8s-node01节点。如下:
1 | [root@k8s-master nodeAffinity]# kubectl delete rs node-affinity-deploy-5c88ffb8ff |
node软亲和性示例
优先调度到满足条件的节点,如果都不满足也会调度到其他节点。
要运行的yaml文件
1 | [root@k8s-master nodeAffinity]# pwd |
运行yaml文件并查看状态
1 | [root@k8s-master nodeAffinity]# kubectl apply -f node_preferred_affinity.yaml |
由上可见,再根据之前打的标签,很容易推断出当前pod会【优先】调度在k8s-node02节点。
node软硬亲和性联合示例
硬亲和性与软亲和性一起使用
要运行的yaml文件
1 | [root@k8s-master nodeAffinity]# pwd |
运行yaml文件并查看状态
1 | [root@k8s-master nodeAffinity]# kubectl apply -f node_affinity.yaml |
由上可见,再根据之前打的标签,很容易推断出k8s-node01、k8s-node02都满足必要条件,但当前pod会【优先】调度在k8s-node01节点。
Pod亲和性
与节点亲和性一样,当前有Pod亲和性/反亲和性都有两种类型,称为requiredDuringSchedulingIgnoredDuringExecution和 preferredDuringSchedulingIgnoredDuringExecution,分别表示“硬”与“软”要求。对于硬要求,如果不满足则pod会一直处于Pending状态。
Pod的亲和性与反亲和性是基于Node节点上已经运行pod的标签(而不是节点上的标签)决定的,从而约束哪些节点适合调度你的pod。
规则的形式是:如果X已经运行了一个或多个符合规则Y的pod,则此pod应该在X中运行(如果是反亲和的情况下,则不应该在X中运行)。当然pod必须处在同一名称空间,不然亲和性/反亲和性无作用。从概念上讲,X是一个拓扑域。我们可以使用topologyKey来表示它,topologyKey 的值是node节点标签的键以便系统用来表示这样的拓扑域。当然这里也有个隐藏条件,就是node节点标签的键值相同时,才是在同一拓扑域中;如果只是节点标签名相同,但是值不同,那么也不在同一拓扑域。★★★★★
也就是说:Pod的亲和性/反亲和性调度是根据拓扑域来界定调度的,而不是根据node节点。★★★★★
1、pod之间亲和性/反亲和性需要大量的处理,这会明显降低大型集群中的调度速度。不建议在大于几百个节点的集群中使用它们。
2、Pod反亲和性要求对节点进行一致的标记。换句话说,集群中的每个节点都必须有一个匹配topologyKey的适当标签。如果某些或所有节点缺少指定的topologyKey标签,可能会导致意外行为。
requiredDuringSchedulingIgnoredDuringExecution中亲和性的一个示例是“将服务A和服务B的Pod放置在同一区域【拓扑域】中,因为它们之间有很多交流”;preferredDuringSchedulingIgnoredDuringExecution中反亲和性的示例是“将此服务的 pod 跨区域【拓扑域】分布”【此时硬性要求是说不通的,因为你可能拥有的 pod 数多于区域数】。
Pod亲和性/反亲和性语法支持以下运算符:In,NotIn,Exists,DoesNotExist。
原则上,topologyKey可以是任何合法的标签键。但是,出于性能和安全方面的原因,topologyKey有一些限制:
1、对于Pod亲和性,在requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution中topologyKey都不允许为空。
2、对于Pod反亲和性,在requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution中topologyKey也都不允许为空。
3、对于requiredDuringSchedulingIgnoredDuringExecution的pod反亲和性,引入了允许控制器LimitPodHardAntiAffinityTopology来限制topologyKey的kubernet.io/hostname。如果你想让它对自定义拓扑可用,你可以修改许可控制器,或者干脆禁用它。
4、除上述情况外,topologyKey可以是任何合法的标签键。
Pod 间亲和通过 PodSpec 中 affinity 字段下的 podAffinity 字段进行指定。而 pod 间反亲和通过 PodSpec 中 affinity 字段下的 podAntiAffinity 字段进行指定。
Pod亲和性/反亲和性的requiredDuringSchedulingIgnoredDuringExecution所关联的matchExpressions下有多个key列表,那么只有当所有key满足时,才能将pod调度到某个区域【针对Pod硬亲和】。
pod亲和性与反亲和性示例
为了更好的演示Pod亲和性与反亲和性,本次示例我们会将k8s-master节点也加入进来进行演示。
准备事项
给node节点打label标签
1 | # 删除已存在标签 |
查询所有节点标签信息
1 | [root@k8s-master ~]# kubectl get node -o wide --show-labels |
如上所述:k8s-master添加了disk-type=ssd,busi-db=redis,busi-use=www标签
k8s-node01添加了disk-type=sata,busi-db=redis,busi-use=www标签
k8s-node02添加了disk-type=ssd,busi-db=etcd,busi-use=www标签
通过deployment运行一个pod,或者直接运行一个pod也可以。为后续的Pod亲和性与反亲和性测验做基础。
1 | ### yaml文件 |
当前pod在k8s-node02节点;其中pod的标签app=myapp-web,version=v1会在后面pod亲和性/反亲和性示例中使用。
pod硬亲和性示例
要运行的yaml文件
1 | [root@k8s-master podAffinity]# pwd |
运行yaml文件并查看状态
1 | [root@k8s-master podAffinity]# kubectl apply -f pod_required_affinity.yaml |
由上可见,yaml文件中为topologyKey: disk-type;虽然k8s-master、k8s-node01、k8s-node02都有disk-type标签;但是k8s-master和k8s-node02节点的disk-type标签值为ssd;而k8s-node01节点的disk-type标签值为sata。因此k8s-master和k8s-node02节点属于同一拓扑域,Pod只会调度到这两个节点上。
pod软亲和性示例
要运行的yaml文件
1 | [root@k8s-master podAffinity]# pwd |
运行yaml文件并查看状态
1 | [root@k8s-master podAffinity]# kubectl apply -f pod_preferred_affinity.yaml |
由上可见,再根据k8s-master、k8s-node01、k8s-node02的标签信息;很容易推断出Pod会优先调度到k8s-master、k8s-node02节点。
pod硬反亲和性示例
要运行的yaml文件
1 | [root@k8s-master podAffinity]# pwd |
运行yaml文件并查看状态
1 | [root@k8s-master podAffinity]# kubectl apply -f pod_required_AntiAffinity.yaml |
由上可见,由于是Pod反亲和测验,再根据k8s-master、k8s-node01、k8s-node02的标签信息;很容易推断出Pod只能调度到k8s-node01节点。
pod软反亲和性示例
要运行的yaml文件
1 | [root@k8s-master podAffinity]# pwd |
运行yaml文件并查看状态
1 | [root@k8s-master podAffinity]# kubectl apply -f pod_preferred_AntiAffinity.yaml |
由上可见,由于是Pod反亲和测验,再根据k8s-master、k8s-node01、k8s-node02的标签信息;很容易推断出Pod会优先调度到k8s-node01节点。
pod亲和性与反亲和性联合示例
要运行的yaml文件
1 | [root@k8s-master podAffinity]# pwd |
运行yaml文件并查看状态
1 | [root@k8s-master podAffinity]# kubectl apply -f pod_podAffinity_all.yaml |
由上可见,根据k8s-master、k8s-node01、k8s-node02的标签信息;很容易推断出Pod只能调度到k8s-master、k8s-node02节点,且会优先调度到k8s-master节点。
相关阅读
2、Kubernetes K8S调度器kube-scheduler详解
完毕!


