
Kubernetes K8S之kube-prometheus概述与部署
主机配置规划
| 服务器名称(hostname) | 系统版本 | 配置 | 内网IP | 外网IP(模拟) |
|---|---|---|---|---|
| k8s-master | CentOS7.7 | 2C/4G/20G | 172.16.1.110 | 10.0.0.110 |
| k8s-node01 | CentOS7.7 | 2C/4G/20G | 172.16.1.111 | 10.0.0.111 |
| k8s-node02 | CentOS7.7 | 2C/4G/20G | 172.16.1.112 | 10.0.0.112 |
prometheus概述
Prometheus是一个开源的系统监控和警报工具包,自2012成立以来,许多公司和组织采用了Prometheus。它现在是一个独立的开源项目,并独立于任何公司维护。在2016年,Prometheus加入云计算基金会作为Kubernetes之后的第二托管项目。
Prometheus性能也足够支撑上万台规模的集群。
Prometheus的关键特性
- 多维度数据模型
- 灵活的查询语言
- 不依赖于分布式存储;单服务器节点是自治的
- 通过基于HTTP的pull方式采集时序数据
- 可以通过中间网关进行时序列数据推送
- 通过服务发现或者静态配置来发现目标服务对象
- 支持多种多样的图表和界面展示,比如Grafana等
架构图
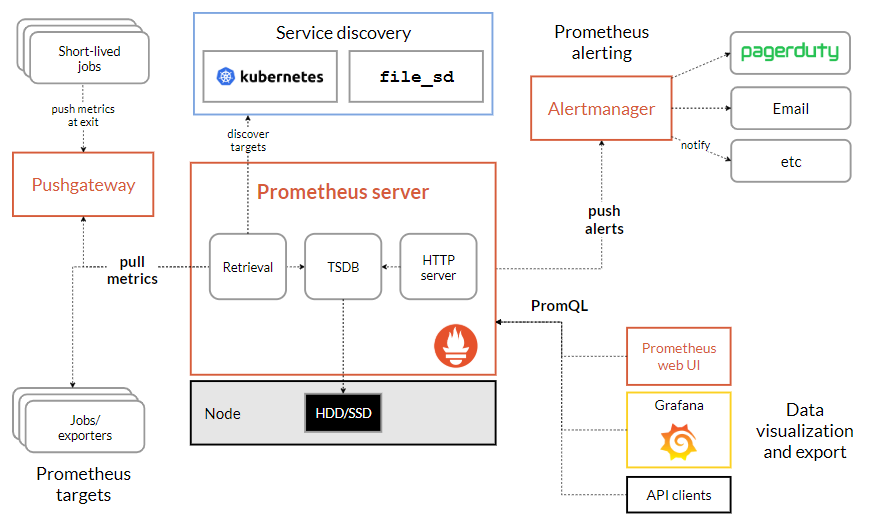
基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。
这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
Prometheus三大套件
- Server 主要负责数据采集和存储,提供PromQL查询语言的支持。
- Alertmanager 警告管理器,用来进行报警。
- Push Gateway 支持临时性Job主动推送指标的中间网关。
服务过程
- Prometheus Daemon负责定时去目标上抓取metrics(指标)数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。
- Prometheus在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。
- Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
- PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
- Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
kube-prometheus部署
kube-prometheus的GitHub地址:
1 | https://github.com/coreos/kube-prometheus/ |
本次我们选择release-0.2版本,而不是其他版本。
kube-prometheus下载与配置修改
下载
1 | [root@k8s-master prometheus]# pwd |
配置修改
1 | # 当前所在目录 |
kube-prometheus镜像版本查看与下载
由于镜像都在国外,因此经常会下载失败。为了快速下载镜像,这里我们下载国内的镜像,然后tag为配置文件中的国外镜像名即可。
查看kube-prometheus的镜像信息
1 | # 当前工作目录 |
执行脚本:镜像下载并重命名【集群所有机器执行】
1 | [root@k8s-master software]# vim download_prometheus_image.sh |
执行脚本后得到如下镜像
1 | [root@k8s-master software]# docker images | grep 'quay.io/coreos' |
kube-prometheus启动
启动prometheus
1 | [root@k8s-master kube-prometheus-0.2.0]# pwd |
启动后svc与pod状态查看
1 | [root@k8s-master ~]# kubectl top node |
kube-prometheus访问
prometheus-service访问
访问地址如下:
1 | http://172.16.1.110:30200/ |
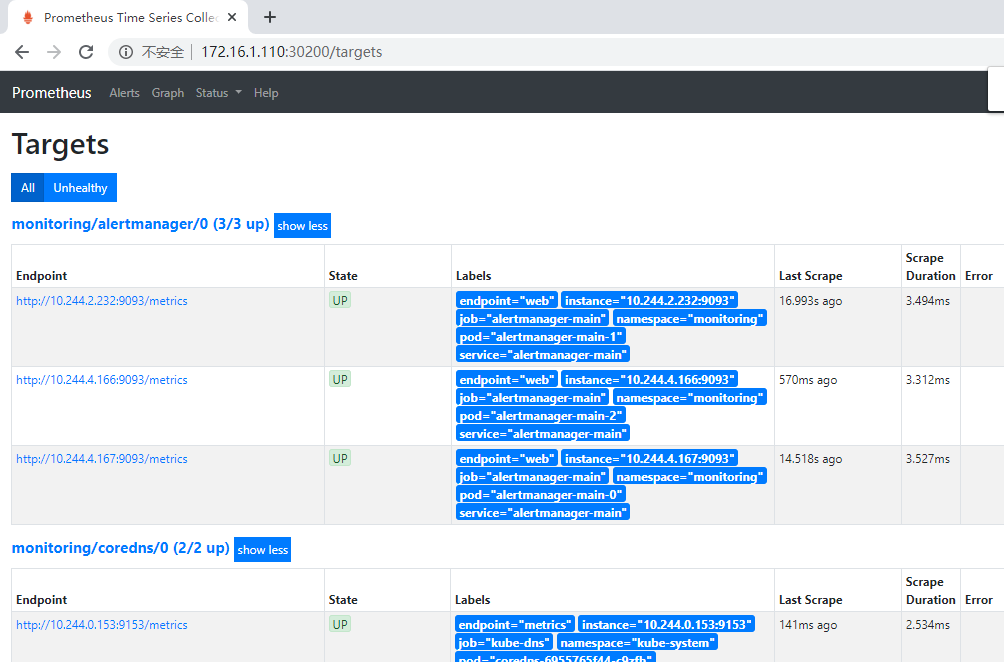
通过访问如下地址,可以看到prometheus已经成功连接上了k8s的apiserver。
1 | http://172.16.1.110:30200/targets |
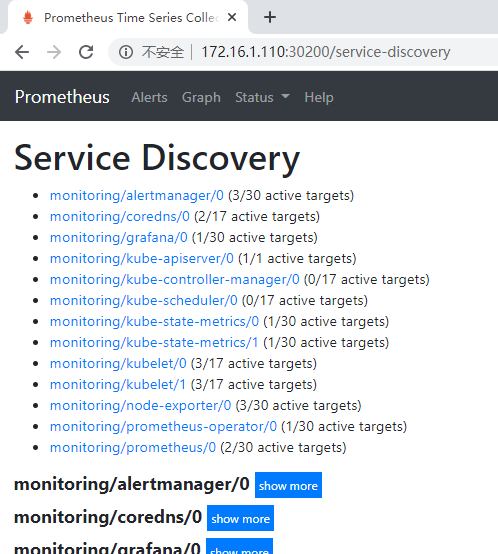
查看service-discovery
1 | http://172.16.1.110:30200/service-discovery |
prometheus自己指标查看
1 | http://172.16.1.110:30200/metrics |
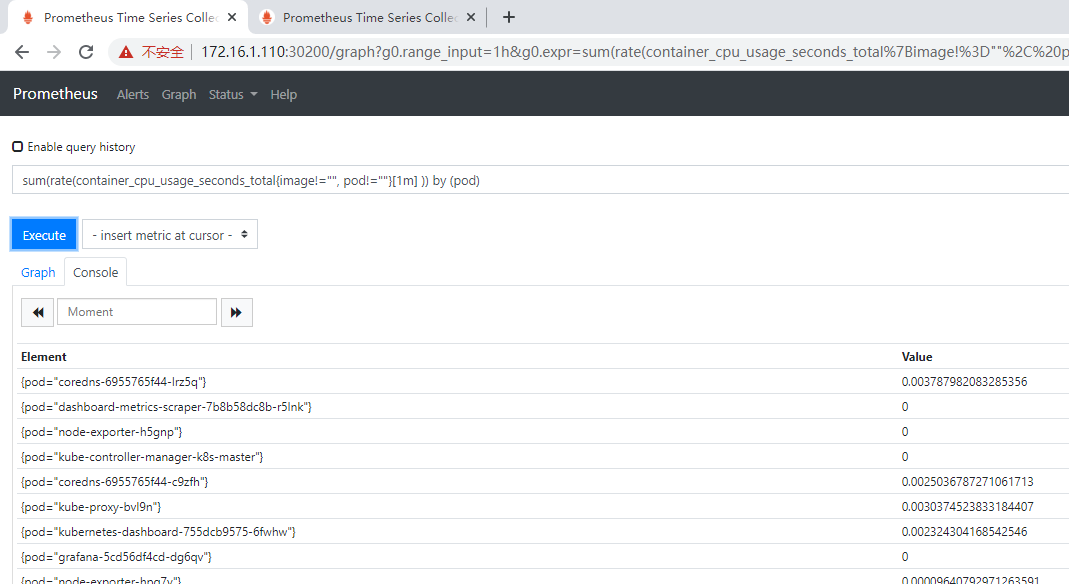
prometheus的WEB界面上提供了基本的查询,例如查询K8S集群中每个POD的CPU使用情况,可以使用如下查询条件查询:
1 | # 直接使用 container_cpu_usage_seconds_total 可以看见有哪些字段信息 |
列表页面
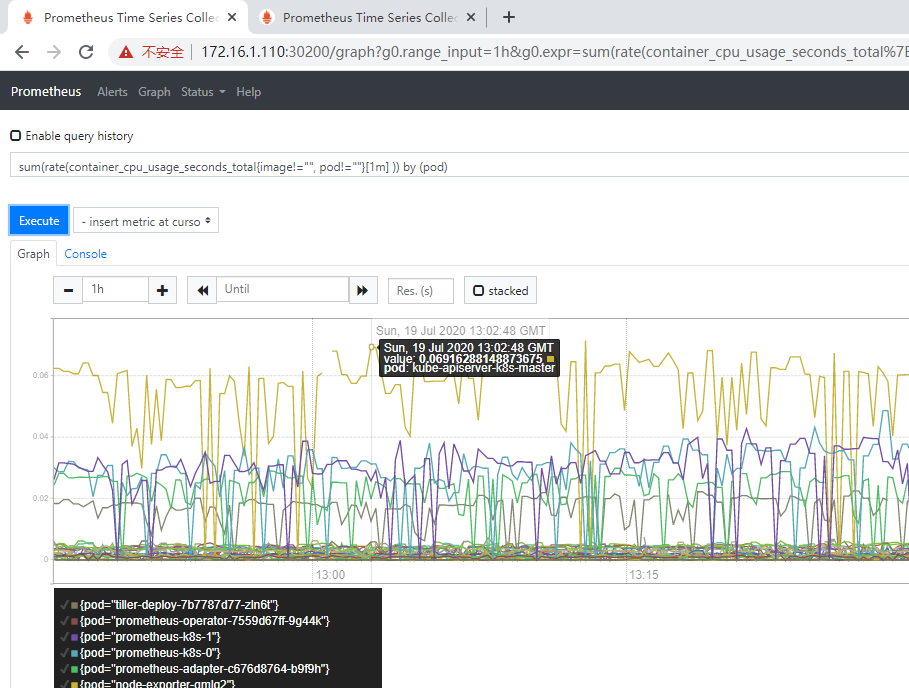
图形页面
grafana-service访问
访问地址如下:
1 | http://172.16.1.110:30100/ |
首次登录时账号密码默认为:admin/admin

添加数据来源
得到如下页面
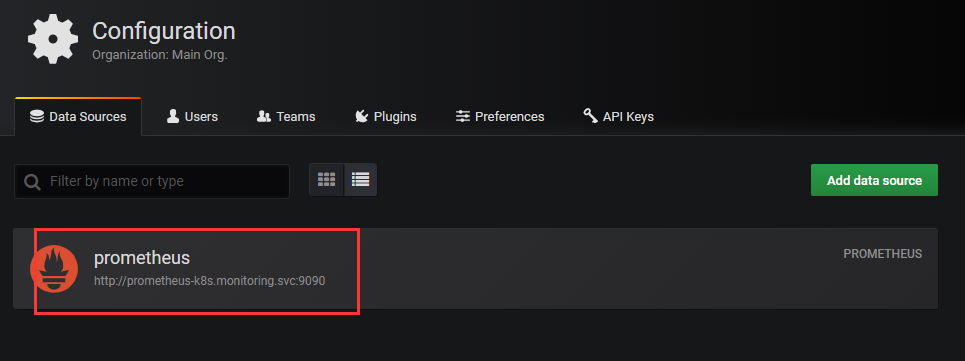
如上,数据来源默认是已经添加好了的
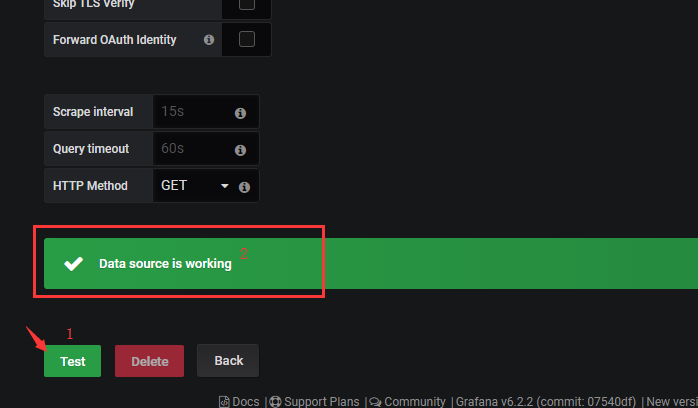
点击进入,拉到下面,再点击Test按钮,测验数据来源是否正常
之后可导入一些模板
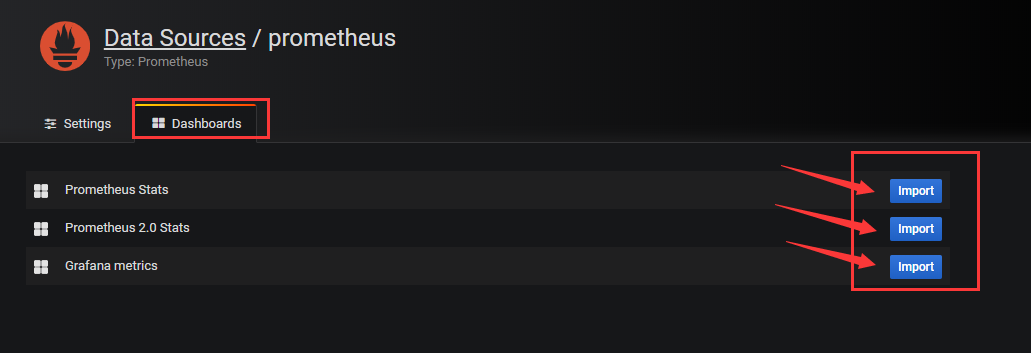
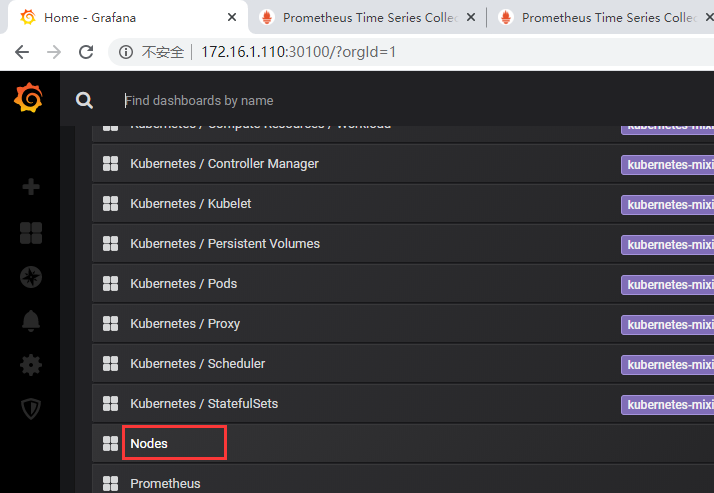
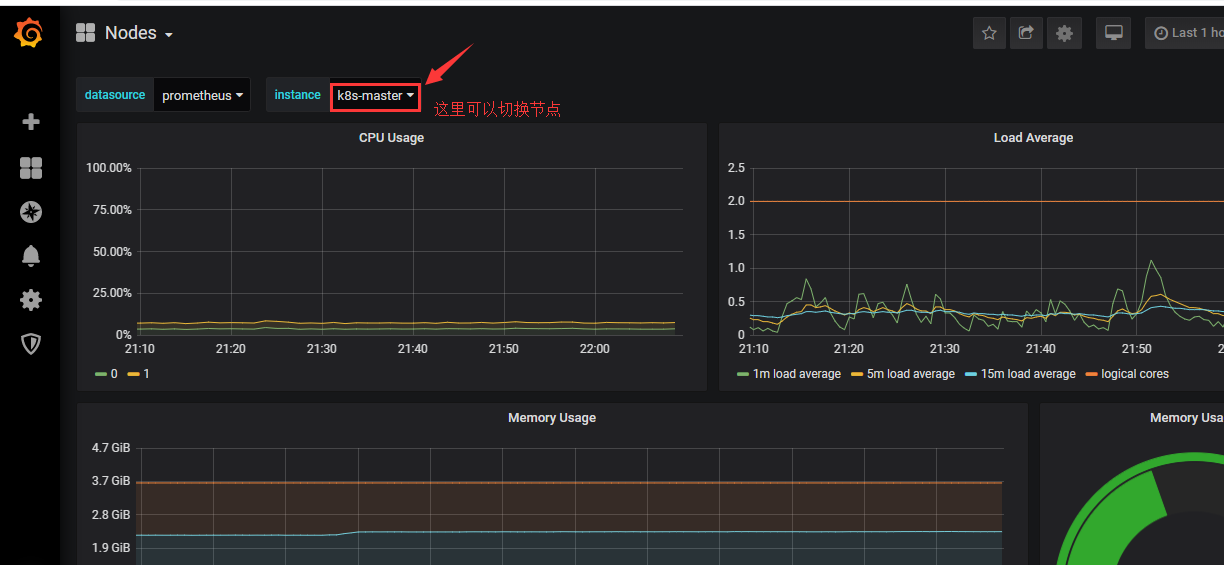
数据信息图像化查看
异常问题解决
如果 kubectl apply -f manifests/ 出现类似如下提示:
1 | unable to recognize "manifests/alertmanager-alertmanager.yaml": no matches for kind "Alertmanager" in version "monitoring.coreos.com/v1" |
那么再次 kubectl apply -f manifests/ 即可;因为存在依赖。
但如果使用的是kube-prometheus:v0.3.0、v0.4.0、v0.5.0版本并出现了上面的提示【反复执行kubectl apply -f manifests/,但一直存在】,原因暂不清楚。
完毕!


