
K8S中Pod的生命周期与ExecAction、TCPSocketAction和HTTPGetAction探针检测
主机配置规划
| 服务器名称(hostname) | 系统版本 | 配置 | 内网IP | 外网IP(模拟) |
|---|---|---|---|---|
| k8s-master | CentOS7.7 | 2C/4G/20G | 172.16.1.110 | 10.0.0.110 |
| k8s-node01 | CentOS7.7 | 2C/4G/20G | 172.16.1.111 | 10.0.0.111 |
| k8s-node02 | CentOS7.7 | 2C/4G/20G | 172.16.1.112 | 10.0.0.112 |
Pod容器生命周期
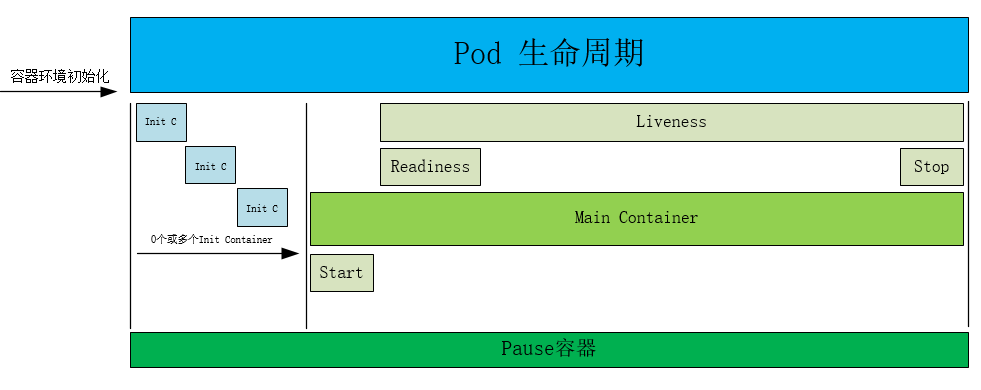
Pause容器说明
每个Pod里运行着一个特殊的被称之为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此他们之间通信和数据交换更为高效。在设计时可以充分利用这一特性,将一组密切相关的服务进程放入同一个Pod中;同一个Pod里的容器之间仅需通过localhost就能互相通信。
PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID。
网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围。
IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信。
UTS命名空间:Pod中的多个容器共享一个主机名;Volumes(共享存储卷)。
Pod中的各个容器可以访问在Pod级别定义的Volumes。
容器探针
探针是由 kubelet 对容器执行的定期诊断。要执行诊断,则需kubelet 调用由容器实现的 Handler。探针有三种类型的处理程序:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- CPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否在容器上运行三种探针执行和做出反应:
- livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为 Success。
- readinessProbe:指示容器是否准备好服务请求【对外接受请求访问】。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
- startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success。
备注:可以以Tomcat web服务为例。
容器重启策略
PodSpec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和 Never。默认为 Always。
Always表示一旦不管以何种方式终止运行,kubelet都将重启;OnFailure表示只有Pod以非0退出码退出才重启;Nerver表示不再重启该Pod。
restartPolicy 适用于 Pod 中的所有容器。restartPolicy 仅指通过同一节点上的 kubelet 重新启动容器。失败的容器由 kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40秒…)重新启动,并在成功执行十分钟后重置。如 Pod 文档中所述,一旦pod绑定到一个节点,Pod 将永远不会重新绑定到另一个节点。
存活(liveness)和就绪(readiness)探针的使用场景
如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活探针;kubelet 将根据 Pod 的restartPolicy 自动执行正确的操作。
如果你希望容器在探测失败时被杀死并重新启动,那么请指定一个存活探针,并指定restartPolicy 为 Always 或 OnFailure。
如果要仅在探测成功时才开始向 Pod 发送流量,请指定就绪探针。在这种情况下,就绪探针可能与存活探针相同,但是 spec 中的就绪探针的存在意味着 Pod 将在没有接收到任何流量的情况下启动,并且只有在探针探测成功后才开始接收流量。
Pod phase(阶段)
Pod 的 status 定义在 PodStatus 对象中,其中有一个 phase 字段。
Pod 的运行阶段(phase)是 Pod 在其生命周期中的简单宏观概述。该阶段并不是对容器或 Pod 的综合汇总,也不是为了做为综合状态机。
Pod 相位的数量和含义是严格指定的。除了本文档中列举的内容外,不应该再假定 Pod 有其他的 phase 值。
下面是 phase 可能的值:
- 挂起(Pending):Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod 的时间和通过网络下载镜像的时间,这可能需要花点时间。
- 运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
- 成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启。
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
- 未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
检测探针-就绪检测
pod yaml脚本
1 | [root@k8s-master lifecycle]# pwd |
创建 Pod,并查看pod状态
1 | [root@k8s-master lifecycle]# kubectl apply -f readinessProbe-httpget.yaml |
查看pod详情
1 | [root@k8s-master lifecycle]# kubectl describe pod readiness-httpdget-pod |
由上可见,容器未就绪。
我们进入pod的第一个容器,然后创建对应的文件
1 | [root@k8s-master lifecycle]# kubectl exec -it readiness-httpdget-pod -c readiness-httpget bash |
之后看pod状态与详情
1 | [root@k8s-master lifecycle]# kubectl get pod -n default -o wide |
由上可见,容器已就绪。
检测探针-存活检测
存活检测-执行命令
pod yaml脚本
1 | [root@k8s-master lifecycle]# pwd |
这个容器生命的前 30 秒,/tmp/healthy 文件是存在的。所以在这最开始的 30 秒内,执行命令 cat /tmp/healthy 会返回成功码。30 秒之后,执行命令 cat /tmp/healthy 就会返回失败状态码。
创建 Pod
1 | [root@k8s-master lifecycle]# kubectl apply -f livenessProbe-exec.yaml |
在 30 秒内,查看 Pod 的描述:
1 | [root@k8s-master lifecycle]# kubectl get pod -o wide |
输出结果显示:存活探测器成功。
35 秒之后,再来看 Pod 的描述:
1 | [root@k8s-master lifecycle]# kubectl get pod -o wide # 显示 RESTARTS 的值增加了 1 |
由上可见,在输出结果的最下面,有信息显示存活探测器失败了,因此这个容器被杀死并且被重建了。
存活检测-HTTP请求
pod yaml脚本
1 | [root@k8s-master lifecycle]# pwd |
创建 Pod,查看pod状态
1 | [root@k8s-master lifecycle]# kubectl apply -f livenessProbe-httpget.yaml |
查看pod详情
1 | [root@k8s-master lifecycle]# kubectl describe pod liveness-httpget-pod |
由上可见,pod存活检测正常
我们进入pod的第一个容器,然后删除对应的文件
1 | [root@k8s-master lifecycle]# kubectl exec -it liveness-httpget-pod -c liveness-httpget bash |
再次看pod状态和详情,可见Pod的RESTARTS从0变为了1。
1 | [root@k8s-master lifecycle]# kubectl get pod -n default -o wide # RESTARTS 从0变为了1 |
由上可见,当liveness-httpget检测失败,重建了Pod容器
存活检测-TCP端口
pod yaml脚本
1 | [root@k8s-master lifecycle]# pwd |
TCP探测正常情况
创建 Pod,查看pod状态
1 | [root@k8s-master lifecycle]# kubectl apply -f livenessProbe-tcp.yaml |
查看pod详情
1 | [root@k8s-master lifecycle]# kubectl describe pod liveness-tcp-pod |
以上是正常情况,可见存活探测成功。
模拟TCP探测失败情况
将上面yaml文件中的探测TCP端口进行如下修改:
1 | livenessProbe: |
删除之前的pod并重新创建,并过一会儿看pod状态
1 | [root@k8s-master lifecycle]# kubectl apply -f livenessProbe-tcp.yaml |
pod详情
1 | [root@k8s-master lifecycle]# kubectl describe pod liveness-tcp-pod |
由上可见,liveness-tcp检测失败,重建了Pod容器。
检测探针-启动检测
有时候,会有一些现有的应用程序在启动时需要较多的初始化时间【如:Tomcat服务】。这种情况下,在不影响对触发这种探测的死锁的快速响应的情况下,设置存活探测参数是要有技巧的。
技巧就是使用一个命令来设置启动探测。针对HTTP 或者 TCP 检测,可以通过设置 failureThreshold * periodSeconds 参数来保证有足够长的时间应对糟糕情况下的启动时间。
示例如下:
pod yaml文件
1 | [root@k8s-master lifecycle]# pwd |
启动pod,并查看状态
1 | [root@k8s-master lifecycle]# kubectl apply -f startupProbe-httpget.yaml |
查看pod详情
1 | [root@k8s-master ~]# kubectl describe pod startup-pod |
有启动探测,应用程序将会有最多 5 分钟(30 * 10 = 300s) 的时间来完成它的启动。一旦启动探测成功一次,存活探测任务就会接管对容器的探测,对容器死锁可以快速响应。 如果启动探测一直没有成功,容器会在 300 秒后被杀死,并且根据 restartPolicy 来设置 Pod 状态。
探测器配置详解
使用如下这些字段可以精确的控制存活和就绪检测行为:
- initialDelaySeconds:容器启动后要等待多少秒后存活和就绪探测器才被初始化,默认是 0 秒,最小值是 0。
- periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。
- timeoutSeconds:探测的超时时间。默认值是 1 秒。最小值是 1。
- successThreshold:探测器在失败后,被视为成功的最小连续成功数。默认值是 1。存活探测的这个值必须是 1。最小值是 1。
- failureThreshold:当探测失败时,Kubernetes 的重试次数。存活探测情况下的放弃就意味着重新启动容器。就绪探测情况下的放弃 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1。
HTTP 探测器可以在 httpGet 上配置额外的字段:
- host:连接使用的主机名,默认是 Pod 的 IP。也可以在 HTTP 头中设置 “Host” 来代替。
- scheme :用于设置连接主机的方式(HTTP 还是 HTTPS)。默认是 HTTP。
- path:访问 HTTP 服务的路径。
- httpHeaders:请求中自定义的 HTTP 头。HTTP 头字段允许重复。
- port:访问容器的端口号或者端口名。如果数字必须在 1 ~ 65535 之间。
相关阅读
2、Kubernetes K8S之Pod 生命周期与init container初始化容器
完毕!


